




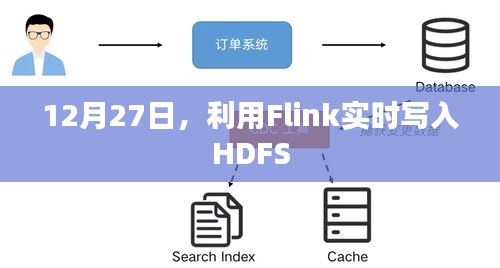
随着大数据技术的不断发展,实时数据处理的需求日益增加,Flink作为一种流处理框架,以其高吞吐量和低延迟的特性,广泛应用于实时计算场景,而Hadoop Distributed File System(HDFS)作为大数据存储的基石,为海量数据提供了可靠的存储服务,本文将介绍如何在12月27日这一天,利用Flink实时将数据写入HDFS。
背景知识
Flink是一个流处理框架,用于处理无界数据流,它提供了数据并行的处理能力,可以处理大规模数据流并生成实时结果,而HDFS是Hadoop的核心组件,用于存储大规模数据,当需要将实时处理的数据结果存储到HDFS时,Flink提供了一个方便的解决方案。
Flink与HDFS的集成
Flink可以通过其内置的HDFS Sink连接器与HDFS集成,通过这个连接器,Flink可以将数据流写入HDFS中的文件,这种集成使得实时处理的数据能够快速地存储到HDFS中,以供后续分析和处理。
实时写入HDFS的步骤
1、环境准备:确保已经安装了Flink和Hadoop集群,并且Flink与Hadoop集群能够正常通信。
2、创建Flink程序:编写Flink程序来处理数据流。
3、配置HDFS Sink:配置Flink程序的输出为HDFS Sink,指定HDFS的目标路径和其他相关参数。

4、启动Flink程序:运行Flink程序,将实时数据流写入HDFS。
5、监控与调优:实时监控Flink程序的运行状态,并根据需要进行调优。
实施细节
以12月27日为例,假设我们需要将某个实时数据流写入HDFS,我们需要确保Flink和Hadoop集群正常运行,并且网络连接正常,我们可以按照以下步骤进行操作:
1、编写Flink程序,处理实时数据流,我们可以使用Flink提供的API来编写程序,例如使用DataStream API来处理数据流。
2、配置HDFS Sink,在Flink程序中,我们需要指定要将数据写入HDFS的目标路径和其他相关参数,例如文件格式、文件命名规则等。
3、运行Flink程序,通过Flink的命令行工具或集成开发环境(IDE)运行程序,将实时数据流写入HDFS。
4、实时监控Flink程序的运行状态,确保数据正常写入HDFS,如果出现性能问题或错误,我们可以根据需要进行调优。
注意事项
1、网络连接:确保Flink集群与Hadoop集群之间的网络连接正常,以保证数据的正常传输。
2、存储空间:确保HDFS有足够的存储空间来存储实时写入的数据。
3、性能调优:根据实际情况进行性能调优,例如调整缓冲区大小、并行度等参数。
通过Flink与HDFS的集成,我们可以实现实时数据的写入存储,在12月27日这一天,我们可以按照上述步骤,利用Flink将实时数据流写入HDFS,为后续的数据分析和处理提供可靠的数据来源。
转载请注明来自西安华剑拓展训练有限公司,本文标题:《Flink实时写入HDFS操作指南,12月27日操作详解》






 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...